
Copyright is a concept that most software developers interact with on a daily basis, whether they are conscious of it or not. Every repository, every library, every framework… they all come with a licence that dictates what you can and cannot do with them. This is so baked into modern software development that few stop to question the underlying premise: should code be copyrightable at all?
For a primer on what copyright is and how software licensing works in practice, see my earlier article: Licensing for Beginners. The short version is this: the moment you create a work, all rights are automatically reserved to you under the Berne Convention. You then use a licence to grant others permission to use, modify, or distribute that work. But this entire framework rests on an assumption that deserves scrutiny, meaning the assumption that code is a creative work deserving of copyright protection in the first place.
What Makes a Work “Creative”?
Copyright exists for creative expression. Literature, music, painting, film. This is not controversial. The controversy begins when we extend this logic to software, because code is fundamentally unlike every other medium that copyright was designed to protect.
A novel conveys ideas, emotions, and narrative. Two authors writing about the same historical event will produce entirely different works. But two programmers implementing the same mathematical function will produce code that is, at a structural level, the same. The difference in syntax between languages is akin to the difference between writing “2 + 2 = 4” and “two plus two equals four,” or in the reverse Polish notation, or whatever else. It is not two distinct creative expressions: it is one mathematical truth expressed in two notations.
Copyright law is built on a categorical distinction: creative works get copyright; functional works get patents. A bridge blueprint is functional. A cake recipe is functional. A mathematical formula is functional. None of these can be copyrighted. Yet software, which is nothing more than an elaborate sequence of mathematical instructions, has been shoehorned into the “literary work” category for want of a better legal box to put it in.
Code is Mathematics
At its core, source code is a set of instructions for a computer to execute. It is, for all practical purposes, indistinguishable from a mathematical algorithm. Consider the following:
func fibonacci(n int) int {
if n <= 1 {
return n
}
return fibonacci(n-1) + fibonacci(n-2)
}
This is not a creative work in any meaningful sense. It is a direct implementation of a mathematical sequence that has been known since the 13th century. The same function could be written in a dozen different programming languages, each looking slightly different, but all expressing the same underlying algorithm. If I translate a novel from English to Polish, I have created a derivative work that requires the original author’s permission. But if I translate an algorithm from Python to Go, have I done anything creative? Or have I merely transcribed a mathematical truth into a different notation?
This is not an abstract question. In 2014, two district courts in the United States ruled in Oracle v. Google that the structure, sequence, and organisation of an API could be copyrighted. This decision rightfully sent shockwaves through the software industry because it suggested that the very way code is organised – that is, the hierarchy of packages, classes, and methods – could be considered a creative expression rather than a functional one. It took years of litigation and a Supreme Court decision in 2021 to establish that fair use applied in that specific case. The fundamental question of whether APIs are copyrightable at all remains unsettled in many jurisdictions, both in and outside the United States.
calculateTax(income) that computes your income
tax based on a government formula, am I expressing creativity? Or am I merely
encoding an objective mathematical relationship that produces the same result
regardless of who writes it?What Stallman Said
Richard Stallman, the founder of the GNU Project and the Free Software Foundation, has spent decades arguing against copyright on software. His 1992 essay “Why Software Should Be Free” remains the most comprehensive case against software ownership ever written. His arguments are worth examining not because he is infallible, but because he has thought about this problem longer and more carefully than almost anyone else.
Refuting the Owner’s Arguments
Stallman identifies two arguments that software owners typically offer in defence of their power: the emotional argument and the economic argument.
The emotional argument goes like this: “I put my sweat, my heart, my soul into this program. It comes from me, and it’s mine!” Stallman dismisses this as an attachment that programmers cultivate when it suits them. Consider how willingly the same programmers sign over all rights to a large corporation for a salary, at which point the emotional attachment mysteriously vanishes. The great artists and artisans of medieval times did not even sign their names to their work. What mattered was that the work was done and the purpose it would serve.
The economic argument is more insidious: “If you don’t allow me to get rich by programming, then I won’t program at all. You’ll be stuck with no programs!” Stallman calls this a bluff, but more importantly he identifies the fallacy in its framing. The argument compares only two outcomes: proprietary software versus no software. It assumes there are no other possibilities. This begs the question entirely. The linkage between software development and ownership is not inherent. It is a consequence of the specific legal policy under scrutiny.
The Toll Road Analogy
To illustrate why this matters, Stallman draws an analogy to road construction. It would be possible to fund all roads with toll booths at every corner. This would provide a great incentive to improve roads, but a toll booth is an artificial obstruction to smooth driving. Artificial, because it is not a consequence of how roads or cars work. Roads without toll booths are cheaper to construct, cheaper to run, safer, and more efficient to use. A toll road is not as good as a free road.
“When the advocates of toll booths propose them as merely a way of raising funds, they distort the choice that is available. Toll booths do raise funds, but they do something else as well: in effect, they degrade the road.”
Software copyright is a toll booth on the information highway. It does raise funds for some developers, but at the cost of degrading the very thing it is supposed to encourage.
The Three Levels of Harm
Stallman’s central thesis is that copyright on software causes three escalating levels of material harm, each with a corresponding psychosocial harm:
-
Fewer people use the program. A copy of a program has nearly zero marginal cost, so in a free market it would have nearly zero price. A licence fee is a significant disincentive. Each time someone chooses to forego using a program because they cannot afford or justify the fee, society loses value without anyone gaining.
- The psychosocial harm: signing a licence agreement means promising to deprive your neighbour of the program so that you can have a copy for yourself. This erodes public spirit. Many users ignore the licences and share anyway, but they feel guilty about it. Forced to choose between being good neighbours and being law-abiding citizens.
-
Users cannot adapt or fix the program. Most proprietary software is distributed as opaque binary numbers; source code is kept secret. If the program has a bug or lacks a feature, you cannot fix it. Stallman recounts how the MIT AI lab received a laser printer from Xerox in the 1980s driven by proprietary software. The lab could not add the notification features they had taken for granted on their old printer, such as no alerts when a job was done, or no notification of paper jams. The printer often went for an hour without being fixed. The system programmers at MIT were as capable as Xerox’s own, but Xerox chose to prevent them from fixing problems.
- The psychosocial harm: it is demoralising to live in a house you cannot rearrange. Stallman asks us to imagine if recipes were hoarded the same way. “How do I change this recipe to take out the salt?” – “How dare you insult my recipe!? I can make that change for a mere 50,000 dollars. I might get around to you in about two years.”
-
Other developers cannot learn from or build on the work. Software development used to be an evolutionary process: a person would take an existing program and modify it for a new purpose, and then another person would do the same. Ownership prevents this, making it necessary to start from scratch each time. Stallman notes that he has met bright computer science students who have never seen the source code of a large program. They cannot learn how to build large systems because they cannot see how others have done it. In any intellectual field, one reaches greater heights by standing on the shoulders of others. In software, however, you can generally stand only on the shoulders of the people in your own company.
- The psychosocial harm: the destruction of scientific cooperation. Japanese oceanographers abandoning their lab on a Pacific island during World War II carefully preserved their work for the invading US Marines and left a note asking them to take good care of it. Conflict for profit has destroyed what international conflict spared.
The Constitutional Reality
Stallman points out that the United States Constitution explicitly states that copyright exists to promote progress, not to reward authors. The Supreme Court has consistently upheld this interpretation, stating in Fox Film v. Doyal that “the sole interest of the United States and the primary object in conferring the [copyright] monopoly lie in the general benefits derived by the public from the labours of authors.” Copyright is a temporary, government-granted monopoly with a specific public purpose, not a natural right. Absolutely nobody in the times of signing the Berne Convention (1880s) imagined copyright lasting more than 100 years, let alone be transferable.
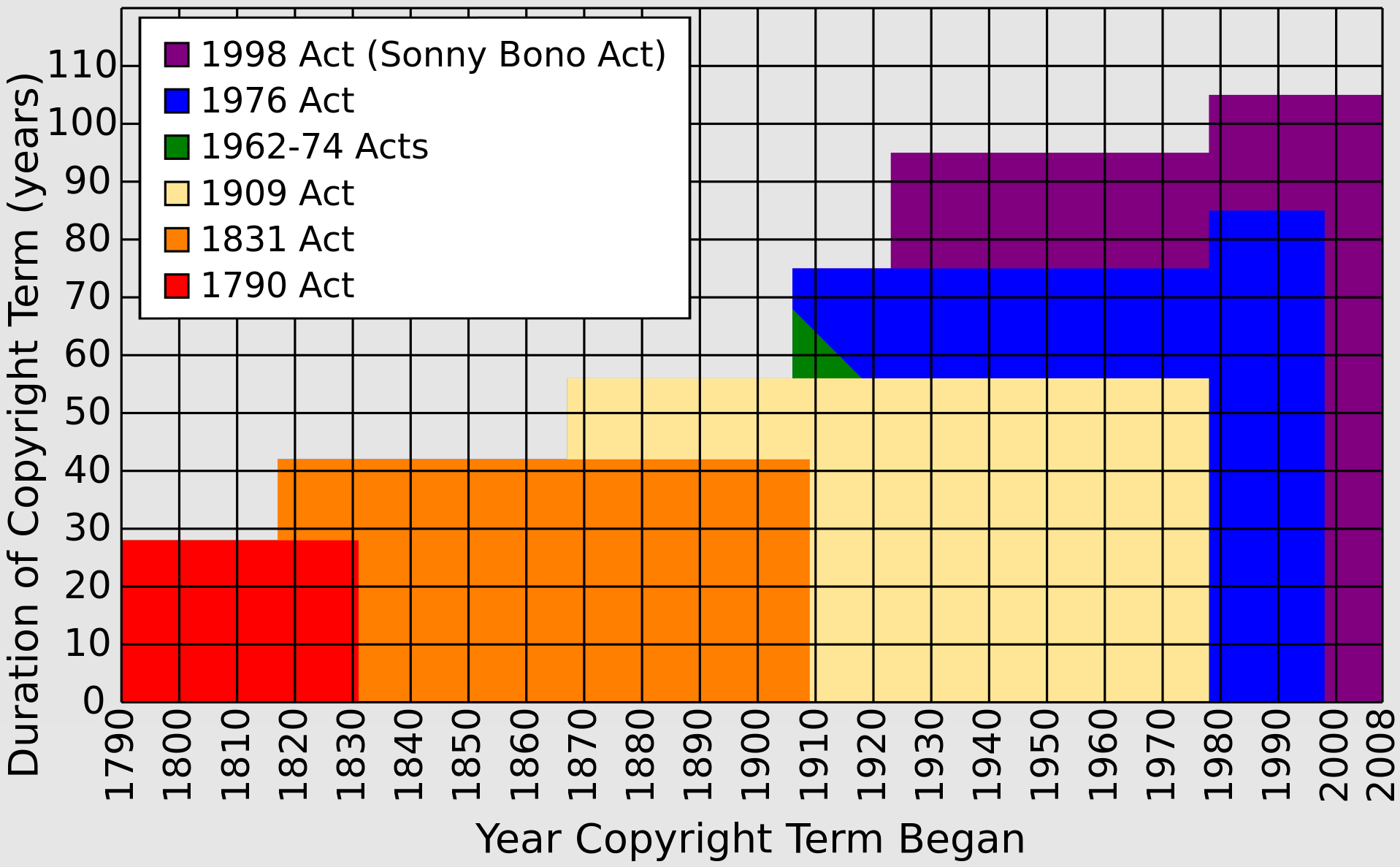
Copyright length extensions over the years in the United States.
Why Don’t You Move to Russia?
Stallman anticipates a common retort: that his views resemble the dreaded communism. He turns this accusation on its head:
“Communism as was practised in the Soviet Union was a system of central control where all activity was regimented, supposedly for the common good, but actually for the sake of the members of the Communist party. And where copying equipment was closely guarded to prevent illegal copying. The American system of intellectual property exercises central control over distribution of a program, and guards copying equipment with automatic copy-protection schemes. By contrast, I am working to build a system where people are free to decide their own actions; in particular, free to help their neighbours, and free to alter and improve the tools which they use in their daily lives. A system based on voluntary cooperation, and decentralisation. Thus, if we are to judge views by their resemblance to Russian Communism, it is the software owners who are the Communists.”
The Four Freedoms
Stallman’s four essential freedoms remain the clearest articulation of what software freedom means in practice:
| Freedom | Right |
|---|---|
| 0 | Run the program for any purpose |
| 1 | Study and modify the source code |
| 2 | Redistribute copies |
| 3 | Distribute your modified versions |
Copyright, as currently enforced, is fundamentally incompatible with these freedoms. Stallman’s response, which is copyleft licensing, was an elegant subversion of the system: use copyright law to guarantee freedom rather than restrict it. But the very need for such a hack underscores the problem. If code were not copyrightable in the first place, there would be no need for licences designed to work around copyright.
The Russian Experience
It is often noted, by Stallman among others, that Russia has historically taken a different approach to software copyright. While the legal situation in Russia is more complex than the popular narrative suggests, Russian law does recognise software as a literary work under its civil code, and the country is a signatory to the Berne Convention. However, it is also true that enforcement has been notoriously weak. In the 1990s and well into the 2000s, Russia’s software piracy rate was estimated at over 90%.
Yet Russia produced Yandex, Kaspersky, VK, Telegram, and a thriving tech sector. These companies did not merely survive without strong copyright enforcement, but flourished. Yandex competes with Google1 in the Russian search market. Kaspersky is a globally recognised cybersecurity brand. The idea that weak copyright enforcement kills innovation is contradicted by this evidence. What it does do is change the business model. When you cannot rely on copyright to protect your product, you must compete on quality, service, and continuous improvement rather than on legal threats and licensing fees.
To be fair, the picture is not entirely rosy. Russian IT associations have pointed out that weak copyright enforcement can also hurt domestic developers, who must compete with free, pirated versions of foreign software. But the fact remains that a multi-billion-dollar software industry emerged in a country where copyright on software was, for all practical purposes, optional for decades. Thus, this is not a theoretical argument, but an empirical observation of a large case study (a former superpower with 140 million people).
The Irony of AI Opposition
Perhaps the most revealing test of people’s actual beliefs about software copyright is the recent panic over AI-generated code.
Before the arrival of large language models like Claude and DeepSeek, the prevailing sentiment in many programming communities was that code should be open, free, and accessible to all. The GNU Public Licence was celebrated. The concept of “information wants to be free” was treated almost as a mantra. Companies like Microsoft were derided for their proprietary practices.
Then AI came along and trained on publicly available code. Code that was often licensed under permissive terms like MIT, Apache, or BSD. And suddenly, many of the same people who championed “open source” found themselves arguing that code should not be used in certain ways. That training an AI on public code was “theft.” That the output of AI models was somehow illegitimate because it was derived from human-written examples.
This is an incoherent position. You cannot simultaneously argue that code should be freely available for anyone to read, learn from, and build upon, as the open source movement has always done, and then argue that an AI reading that same code and learning from it is somehow different. The AI is doing exactly what a human programmer does when they browse GitHub: reading code, understanding patterns, and applying that knowledge to write new code. If code is functional and mathematical, as argued above, then an AI learning from it is no different from a human learning from it. And if code is creative and copyrightable, then the entire open source movement rests on a shaky legal foundation, because every open source project is built on top of countless prior works whose authors never explicitly consented to their use.
The anti-AI crowd cannot have it both ways. The same logic that justifies open source, meaning code is a shared resource that everyone benefits from, also justifies AI training. The fact that this makes some people uncomfortable does not make them wrong about copyright, but it does reveal that their opposition is emotional rather than principled. It also appears to be largely based on a highly limited and uneducated understanding of how generative adversarial networks (GANs) work in general.
-
If you believe code is creative enough to be copyrighted, then open source licensing is built on a foundation of sand, because every free software project incorporates ideas and patterns from prior creative work without explicit permission.
-
If you believe code is functional and should be free, then AI training is not theft. It is exactly what the open source movement has always advocated for.
These positions are mutually exclusive. Pick one, and only one.
The refutation to what was just said is that companies can use AI as a free “clear copyright” card to use in their proprietary code. Indeed, Microsoft and many other tech giants seem to be using AI that way.
This is also exactly why software should not be copyrighted, so that proprietary code does not exist. Elimination of software copyright would eliminate this category of abuse in the same sling.
Conclusion
Copyright on software rests on a questionable foundation. The law treats code as a literary work, but code is fundamentally different from literature. Literature expresses ideas and emotions; code expresses algorithms and processes. Literature is consumed by humans; code is executed by machines. The two categories are not analogous, and treating them as such has led to decades of legal confusion and a regulatory framework that enriches corporations at the expense of developers and the public.
The success of the free software movement, the Russian tech industry’s growth without strong copyright enforcement, and the philosophical incoherence of the anti-AI position all point in the same direction: the copyright system as applied to software is broken. Whether the solution is weaker copyright, copyleft, or a completely different legal framework is a question that deserves serious debate. But the debate cannot begin until we admit that the current system is not working, and that the question of whether code should be copyrighted at all is far from settled.
-
Yandex even has better reverse image search, since Google has purposely gimped its reverse image search capabilities after it repeatedly kept mislabeling Negroes as gorillas. ↩︎